INSTALACIÓN DEL SGBD ORACLE 11G (RHEL/CentOS/Fedora)
Este es un pequeño manual destinado a todos aquellos que quieran realizar una instalación del motor de bases de datos de Oracle en una distribución de GNU/Linux
Requerimientos del sistema:
La
cantidad mínima de RAM que se necesita es de 1Gb.
La cantidad recomendada es cualquier configuración que tenga más
de 1Gb.
Espacio
mínimo libre en disco para la instalación 3.95Gb más el espacio
libre para datos de 1.7Gb, y la recomendada es de una configuración
mayor a la mínima.
Cualquier
sistema operativo es soportado para la configuración mínima.
Descripción general:
Oracle
es un manejador de base de datos relacional que hace uso de los
recursos del sistema informático en todas las arquitecturas de
hardware, para garantizar su aprovechamiento al máximo en ambientes
cargados de información. Oracle corre en computadoras personales
(PC), microcomputadoras, mainframes y computadoras con procesamiento
paralelo masivo. Corre automáticamente en más de 80 arquitecturas
de hardware y software distinto sin tener la necesidad de cambiar
una sola línea de código. Esto es porque más el 80% de los
códigos internos de Oracle son iguales a los establecidos en todas
las plataformas de sistemas operativos.
Oracle
también da soporte para dispositivos en bruto (Raw devices), tiene la
ventaja de que la ejecución es un 50% más rápido que sobre un
dispositivo con un sistema de archivos. Las desventajas son que: El
respaldo de una base de datos que utiliza un dispositivo en bruto no
es tan simple y no es soportado por todos los proveedores de BackUp;
Los nombres de archivos están limitados a una sintaxis específica
y solo se permite un archivo por partición del dispositivo. Además,
en la mayoría de los casos que existen problemas de rendimiento se
debe a indices mal puestos o a extensiones excesivas de tabla,
etc.
Bueno, basta de cháchara, vamos manos a la obra:
Instalación (Pasos previos):
Antes
de poder comenzar con la instalación es necesario realizar varias
tareas, como instalar dependencias y configurar determinados
parámetros del kernel y agregar y configurar los usuarios del SO
que utiliza el motor.
Primero nos aseguramos de que tengamos
instaladas todas las dependencias en el sistema. La lista de las
dependencias necesarias es la siguiente (No existe una lista para CentOS o Fedora, pero como ambas están basadas o soportadas por RedHat vamos
a tomar las dependencias de ésta):
binutils-2.17.50.0.6
compat-libstdc++-33-3.2.3
elfutils-libelf-0.125
elfutils-libelf-devel-0.125
elfutils-libelf-devel-static-0.125
gcc-4.1.2
gcc-c++-4.1.2
glibc-2.5-24
glibc-common-2.5
glibc-devel-2.5
glibc-headers-2.5
kernel-headers-2.6.18
ksh-20060214
libaio-0.3.106
libaio-devel-0.3.106
libgcc-4.1.2
libgomp-4.1.2
libstdc++-4.1.2
libstdc++-devel-4.1.2
make-3.81
sysstat-7.0.2
unixODBC-2.2.11
unixODBC-devel-2.2.11
Para
verificar las dependencias ejecutamos el comando siguiente como
superusuario:
#
rpm -q binutils compat-libstdc++ elfutils-libelf
elfutils-libelf-devel elfutils-libelf-devel-static
gcc gcc-c++ glibc glibc-common glibc-devel glibc-headers
kernel-headers ksh libaio-devel
libaio libgcc libgomp
libstdc++ libstdc++-devel make sysstat unixODBC unixODBC-devel
binutils-2.21.51.0.6-6.fc15.i686
package
compat-libstdc++ is not installed
elfutils-libelf-0.152-1.fc15.i686
package
elfutils-libelf-devel is not installed
package
elfutils-libelf-devel-static is not installed
package
gcc is not installed
package
gcc-c++ is not installed
glibc-2.14-5.i686
glibc-common-2.14-5.i686
package
glibc-devel is not installed
package
glibc-headers is not installed
package
kernel-headers is not installed
package
ksh is not installed
package
libaio-devel is not installed
libaio-0.3.109-3.fc15.i686
libgcc-4.6.0-10.fc15.i686
package
libgomp is not installed
libstdc++-4.6.0-10.fc15.i686
package
libstdc++-devel is not installed
make-3.82-4.fc15.i686
package
sysstat is not installed
package
unixODBC is not installed
package
unixODBC-devel is not installed
La
salida del comando nos indica, en el caso de que tengamos instaladas
las dependencias, su versión, y en caso contrario nos indica que no
se encuentran instaladas. Procedemos a instalarlas ejecutando el
siguiente comando:
#
yum install compat-libstdc++ elfutils-libelf-devel
elfutils-libelf-devel-static gcc gcc-c++ glibc-devel
glibc-headers kernel-headers pdksh
libaio-devel libgomp
libstdc++-devel sysstat unixODBC unixODBC-devel
Loaded
plugins: langpacks, presto, refresh-packagekit
Setting
up Install Process
No
package compat-libstdc++ available.
Resolving
Dependencies
-->
Running transaction check
--->
Package elfutils-libelf-devel.i686 0:0.152-1.fc15 will be installed
--->
Package elfutils-libelf-devel-static.i686 0:0.152-1.fc15 will be
installed
--->
Package gcc.i686 0:4.6.0-10.fc15 will be installed
-->
Processing Dependency: cpp = 4.6.0-10.fc15 for package:
gcc-4.6.0-10.fc15.i686
-->
Processing Dependency: cloog-ppl >= 0.15 for package:
gcc-4.6.0-10.fc15.i686
-->
Processing Dependency: libmpc.so.2 for package:
gcc-4.6.0-10.fc15.i686
--->
Package gcc-c++.i686 0:4.6.0-10.fc15 will be installed
--->
Package glibc-devel.i686 0:2.14-5 will be installed
--->
Package glibc-headers.i686 0:2.14-5 will be installed
--->
Package kernel-headers.i686 0:2.6.40.3-0.fc15 will be installed
--->
Package ksh.i686 0:20110505-2.fc15 will be installed
--->
Package libaio-devel.i686 0:0.3.109-3.fc15 will be installed
--->
Package libgomp.i686 0:4.6.0-10.fc15 will be installed
--->
Package libstdc++-devel.i686 0:4.6.0-10.fc15 will be installed
--->
Package sysstat.i686 0:9.0.6.1-14.fc15 will be installed
--->
Package unixODBC.i686 0:2.2.14-13.fc15 will be installed
--->
Package unixODBC-devel.i686 0:2.2.14-13.fc15 will be installed
-->
Running transaction check
--->
Package cloog-ppl.i686 0:0.15.9-3.fc15 will be installed
-->
Processing Dependency: libppl.so.9 for package:
cloog-ppl-0.15.9-3.fc15.i686
-->
Processing Dependency: libppl_c.so.4 for package:
cloog-ppl-0.15.9-3.fc15.i686
--->
Package cpp.i686 0:4.6.0-10.fc15 will be installed
--->
Package libmpc.i686 0:0.8.3-0.3.svn855.fc15 will be installed
-->
Running transaction check
--->
Package ppl.i686 0:0.11.2-1.fc15 will be installed
-->
Processing Dependency: libpwl.so.5 for package:
ppl-0.11.2-1.fc15.i686
-->
Running transaction check
--->
Package ppl-pwl.i686 0:0.11.2-1.fc15 will be installed
-->
Finished Dependency Resolution
Dependencies
Resolved
===============================================================================
Package
Arch Version Repository
Size
===============================================================================
Installing:
elfutils-libelf-devel
i686 0.152-1.fc15 fedora 31 k
elfutils-libelf-devel-static
i686 0.152-1.fc15 fedora 66 k
gcc
i686 4.6.0-10.fc15 updates
11 M
gcc-c++
i686 4.6.0-10.fc15 updates 4.9 M
glibc-devel
i686 2.14-5 updates 977 k
glibc-headers
i686 2.14-5 updates 605 k
kernel-headers
i686 2.6.40.3-0.fc15 updates 753 k
ksh
i686 20110505-2.fc15 updates
756 k
libaio-devel
i686 0.3.109-3.fc15 fedora 12 k
libgomp
i686 4.6.0-10.fc15 updates 90 k
libstdc++-devel
i686 4.6.0-10.fc15 updates 1.3 M
sysstat
i686 9.0.6.1-14.fc15 fedora 212 k
unixODBC
i686 2.2.14-13.fc15 fedora 377 k
unixODBC-devel
i686 2.2.14-13.fc15 fedora 52 k
Installing
for dependencies:
cloog-ppl
i686 0.15.9-3.fc15 fedora 93 k
cpp
i686 4.6.0-10.fc15 updates
3.9 M
libmpc
i686 0.8.3-0.3.svn855.fc15 fedora 49
k
ppl
i686 0.11.2-1.fc15 fedora
1.5 M
ppl-pwl
i686 0.11.2-1.fc15 fedora 35 k
Transaction
Summary
===============================================================================
Install
19 Package(s)
Total
size: 27 M
Total
download size: 23 M
Installed
size: 71 M
Is
this ok [y/N]: y
Downloading
Packages:
Setting
up and reading Presto delta metadata
Processing
delta metadata
Package(s)
data still to download: 23 M
(1/17):
elfutils-libelf-devel-0.152-1.fc15.i686.rpm | 31 kB 00:01
(2/17):
elfutils-libelf-devel-static-0.152-1.fc15.i686. | 66 kB 00:00
(3/17):
gcc-4.6.0-10.fc15.i686.rpm | 11 MB 02:54
(4/17):
gcc-c++-4.6.0-10.fc15.i686.rpm | 4.9 MB 01:28
(5/17):
glibc-devel-2.14-5.i686.rpm | 977 kB 00:35
(6/17):
glibc-headers-2.14-5.i686.rpm | 605 kB 00:19
(7/17):
kernel-headers-2.6.40.3-0.fc15.i686.rpm | 753 kB 00:29
(8/17):
ksh-20110505-2.fc15.i686.rpm | 756 kB 00:12
(9/17):
libaio-devel-0.3.109-3.fc15.i686.rpm | 12 kB 00:01
(10/17):
libgomp-4.6.0-10.fc15.i686.rpm | 90 kB 00:02
(11/17):
libmpc-0.8.3-0.3.svn855.fc15.i686.rpm | 49 kB 00:01
(12/17):
libstdc++-devel-4.6.0-10.fc15.i686.rpm | 1.3 MB 00:19
(13/17):
ppl-0.11.2-1.fc15.i686.rpm | 1.5 MB 00:16
(14/17):
ppl-pwl-0.11.2-1.fc15.i686.rpm | 35 kB 00:00
(15/17):
sysstat-9.0.6.1-14.fc15.i686.rpm | 212 kB 00:02
(16/17):
unixODBC-2.2.14-13.fc15.i686.rpm | 377 kB 00:08
(17/17):
unixODBC-devel-2.2.14-13.fc15.i686.rpm | 52 kB 00:00
-------------------------------------------------------------------------------
Total
55 kB/s | 23 MB 07:07
Running
rpm_check_debug
Running
Transaction Test
Transaction
Test Succeeded
Running
Transaction
Installing :
elfutils-libelf-devel-0.152-1.fc15.i686 1/19
Installing :
libstdc++-devel-4.6.0-10.fc15.i686 2/19
Installing :
kernel-headers-2.6.40.3-0.fc15.i686 3/19
Installing :
libmpc-0.8.3-0.3.svn855.fc15.i686 4/19
Installing :
glibc-headers-2.14-5.i686 5/19
Installing :
glibc-devel-2.14-5.i686 6/19
Installing :
cpp-4.6.0-10.fc15.i686 7/19
Installing :
ppl-pwl-0.11.2-1.fc15.i686 8/19
Installing :
ppl-0.11.2-1.fc15.i686 9/19
Installing :
cloog-ppl-0.15.9-3.fc15.i686 10/19
Installing :
libgomp-4.6.0-10.fc15.i686 11/19
Installing :
gcc-4.6.0-10.fc15.i686 12/19
Installing :
unixODBC-2.2.14-13.fc15.i686 13/19
Installing :
unixODBC-devel-2.2.14-13.fc15.i686 14/19
Installing :
elfutils-libelf-devel-static-0.152-1.fc15.i686 15/19
Installing :
libaio-devel-0.3.109-3.fc15.i686 16/19
Installing :
gcc-c++-4.6.0-10.fc15.i686 17/19
Installing :
sysstat-9.0.6.1-14.fc15.i686 18/19
Installing :
ksh-20110505-2.fc15.i686 19/19
Installed:
elfutils-libelf-devel.i686
0:0.152-1.fc15
elfutils-libelf-devel-static.i686
0:0.152-1.fc15
gcc.i686
0:4.6.0-10.fc15
gcc-c++.i686
0:4.6.0-10.fc15
glibc-devel.i686
0:2.14-5
glibc-headers.i686
0:2.14-5
kernel-headers.i686
0:2.6.40.3-0.fc15
ksh.i686
0:20110505-2.fc15
libaio-devel.i686
0:0.3.109-3.fc15
libgomp.i686
0:4.6.0-10.fc15
libstdc++-devel.i686
0:4.6.0-10.fc15
sysstat.i686
0:9.0.6.1-14.fc15
unixODBC.i686
0:2.2.14-13.fc15
unixODBC-devel.i686
0:2.2.14-13.fc15
Dependency
Installed:
cloog-ppl.i686
0:0.15.9-3.fc15 cpp.i686 0:4.6.0-10.fc15
libmpc.i686
0:0.8.3-0.3.svn855.fc15 ppl.i686 0:0.11.2-1.fc15
ppl-pwl.i686
0:0.11.2-1.fc15
Complete!
Ahora
todos las dependencias ya están instaladas a excepción de
compat-libstdc++,
que vamos a instalar más adelante porque no está en los
repositorios de la actual distribución.
Ahora
toca configurar los grupos y usuarios para Oracle. Ellos son:
El
grupo de inventario (típicamente, oinstall)
El
grupo OSDBA (típicamente, dba)
El
dueño del software (típicamente, oracle)
El
grupo OSOPER (opcional. Típicamente, oper)
Para
agregar los grupo ejecutamos los siguientes comandos:
#
groupadd oinstall
#
groupadd dba
Y
luego para crear el usuario y agregarlo al grupo correspondiente:
#
useradd -g oinstall -G dba oracle
Pedirá
la contraseña para el usuario e ingresamos “oracle” (o cualquier
otra) y listo. Si ejecutamos el siguiente comando:
#
id oracle
La
salida debe ser algo parecido a esto:
uid=501(oracle)
gid=503(oinstall) groups=503(oinstall),501(dba)
El
paso siguiente es ver si determinados parámetros del núcleo están
correctos. En la guía de instalación de Oracle especifica cuales
son y sus valores:
Parámetro
|
Valor
mínimo
|
Archivo
|
semmsl
semmns
semopm
semmn
|
250
3200
100
128
|
/proc/sys/kernel/sem
|
shmall
|
2097152
|
/proc/sys/kernel/shmall
|
shmmax
|
Puede
ser 4 GB - 1 byte, o la mitad del tamaño de la memoria física
(en bytes), el que sea menor.
Defecto:
536870912
|
/proc/sys/kernel/shmmax
|
shmmni
|
4096
|
/proc/sys/kernel/shmmni
|
file-max
|
512
* PROCESSES
|
/proc/sys/fs/file-max
|
ip_local_port_range
|
Min:
9000 Max: 65500
|
/proc/sys/net/ipv4/ip_local_port_range
|
rmem_default
|
262144
|
/proc/sys/net/core/rmem_default
|
rmem_max
|
4194304
|
/proc/sys/net/core/rmem_max
|
wmem_default
|
262144
|
/proc/sys/net/core/wmem_default
|
wmem_max
|
1048576
|
/proc/sys/net/core/wmem_max
|
aio-max-nr
|
Máximo:
1048576
|
/proc/sys/fs/aio-max-nr
|
Para
poder comprobar el estado de estos valores se pueden ejecutar los
siguientes comandos:
Para:
semmsl, semmns, semopm y semmn
#
/sbin/sysctl -a | grep sem
Si
se cambia el valor del parámetro que sigue a “grep” por los
parámetros de la lista obtenemos el valor dichos parámetros del
núcleo.
#
/sbin/sysctl -a | grep shmall
#
/sbin/sysctl -a | grep shmmax
#
/sbin/sysctl -a | grep shmmni
#
/sbin/sysctl -a | grep file-max
#
/sbin/sysctl -a | grep ip_local_port_range
#
/sbin/sysctl -a | grep rmem_default
#
/sbin/sysctl -a | grep rmem_max
#
/sbin/sysctl -a | grep wmem_default
#
/sbin/sysctl -a | grep wmem_max
Ahora
lo que hacemos, si encontramos algún parámetro que no es el
adecuado, es editar el archivo /etc/sysctl.conf
mediante el comando nano o vi:
#
nano /etc/sysctl.conf
E
ingresamos los siguientes valores solo si los parámetros actuales
tienen un valor menor.
fs.aio-max-nr
= 1048576
fs.file-max = 6815744
kernel.shmall =
2097152
kernel.shmmax = 536870912
kernel.shmmni =
4096
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range
= 9000 65500
net.core.rmem_default = 262144
net.core.rmem_max =
4194304
net.core.wmem_default = 262144
net.core.wmem_max =
1048586
Guardamos
los cambios en el archivo y reiniciamos la computadora.
Ahora
vamos a darle “superpoderes” al usuario oracle editando el
archivo /etc/security/limits.conf mediante el comando nano o vi:
#
nano /etc/security/limits.conf
Y
añadimos las siguientes líneas al final del archivo:
oracle
soft nproc 2047
oracle hard nproc
16384
oracle soft nofile 1024
oracle
hard nofile 65536
Guardamos
los cambios y listo.
Ahora
editamos el archivo /etc/pam.d/login:
#
nano /etc/pam.d/login
Y
añadimos al final (si es que ya no está) la siguiente línea:
session
required pam_limits.so
Guardamos
y listo.
Ahora
falta configurar el ambiente para el usuario oracle. Para ello nos
logueamos en un terminal con el usuario oracle y ejecutamos el
siguiente comando:
$
nano .bash_profile
Y
colocamos debajo de la sección “User specific environment and
startup programs” lo siguiente:
umask
022
Ya
tenemos configurado los usuarios, los grupos, los parámetros del
kernel y algunas opciones para mejorar el rendimiento.
Ahora
nos logueamos al sistema con el usuario oracle que creamos,
ingresamos a la web de Oracle y descargamos los instaladores, luego
descomprimimos los archivos de instalación (parte 1 y parte 2) y nos
movemos al directorio donde los descomprimimos con el siguiente
comando:
$
cd database/
$
./runInstaller
Starting
Oracle Universal Installer...
Checking
Temp space: must be greater than 80 MB. Actual 16043 MB Passed
Checking
swap space: must be greater than 150 MB. Actual 2111 MB Passed
Checking
monitor: must be configured to display at least 256 colors. Actual
16777216 Passed
Preparing
to launch Oracle Universal Installer from
/tmp/OraInstall2011-09-06_12-46-45AM. Please wait ...
Finalmente
se muestra la primer pantalla del asistente de instalación.
Aquí
nos pide nuestra dirección de email y nuestra contraseña de usuario
de la web de oracle para recibir notificaciones sobre actualizaciones
de seguridad y soporte. Quitamos la selección de esa casilla e
ingresamos nuestro email y hacemos clic en “Next”. La siguiente
pantalla aparece:
En
esta pantalla seleccionamos la primer opción puesto que luego de
instalar el motor de base de datos vamos a crear una base de datos.
La segunda opción instala solo el motor pero no nos guía para crear
una base de datos. La tercer opción es para actualizar una
instalación preexistente. Presionamos “Next”.
Aquí
nos solicita el tipo de computadora donde queremos instalar y nos
presenta dos opciones posibles “Desktop class” que es para
instalar el motor con las opciones por defecto para un ordenador de
escritorio o notebook y tener el servicio corriendo lo más rápido
posible. La otra opción “Server class” es para instalar el motor
en un servidor de producción y con opciones avanzadas. Para los
propósitos de éste trabajo seleccionamos “Server class” y damos
a “Next”.
En
esta pantalla nos pregunta acerca de la configuración para “Grid”
que es un conjunto de bases de datos colaborando entre si. Las dos
opciones posibles son “Single instance database instalaltion” y
“Real Application Clusters database installation”. En la primera
tenemos una única instancia en nuestra computadora y con la otra
podremos configurar una red de bases de datos. Seleccionamos la
primer opción y hacemos clic en “Next”.
En
esta pantalla nos solicita el tipo de instalación “Typical
install” y “Advanced install”. Seleccionamos la segunda opción
para disponer de las opciones de instalación avanzada y presionamos
“Next”.
Ahora
nos pide el idioma de instalación para el motor. Seleccionamos
“Spanish” en la lista de la izquierda y hacemos clic en la flecha
hacia la derecha para agregarla a la lista de la derecha. El idioma
inglés no puede ser removido de la lista de la derecha. Presionamos
“Next”
En
la pantalla actual nos solicita el tipo de edición que queremos
instalar. Seleccionamos “Enterprise edition” y si hacemos clic en
“Select options” podremos agregar o quitar algunos componentes
adicionales. Dejamos seleccionados los que están por defecto que
son: “Oracle partitioning”, “Oracle OLAP”, “Oracle Data
Mining RDBMS Files” y “Oracle Real Applications Testing”.
Presionamos “Ok” y luego “Next”.
En
esta pantalla nos pregunta primero el directorio de base y segundo el
directorio donde se van a instalar todos los programas que componen
al motor. Dejamos los que están por defecto y presionamos “Next”.
Ahora
nos solicita que ingresemos la ruta del directorio de inventario que
es donde Oracle instala los componentes adicionales para que las
diferentes instalaciones de Oracle lo compartan. Además nos pide el
grupo de usuarios que tienen permiso sobre ese directorio. Dejamos
las opciones por defecto y presionamos “Next”.
En
la pantalla actual nos pregunta acerca del tipo de base de datos que
deseamos configurar. Tenemos dos opciones. La primera “General
purpose / Transaction processing” que es para una base de datos de
propósito general y para el soporte de transacciones pesadas. La
segunda “Data warehousing” que es para el almacenamiento masivo
de datos a lo largo del tiempo para su posterior uso en la toma de
decisiones, como por ejemplo patrones de compra de clientes, llamados
a los mismos, etc y proporciona un acceso rápido a grandes volúmenes
de datos. Seleccionamos la primer opción y damos a “Next”.
En
esta pantalla nos solicita la identificación de nuestra instalación
de Oracle. El identificador global y el identificador de servicio.
Esto es para identificar una instalación puntual dentro de una red
de bases de datos y el segundo campo indica el identificador local
para que otras instancias de instalación hagan referencia a la
actual instalación. Como es la única instancia que vamos a instalar
dejamos las opciones por defecto.
En
la pantalla actual nos da la opción de que el motor gestione la
memoria automáticamente según el uso del mismo o nos deja a nuestro
criterio la definición del uso de memoria. La opción por defecto es
la gestión automática. En la pestaña “Character sets” nos da
la opción de especificar un juego de caracteres para la base de
datos. Dejamos la opción por defecto que toma el juego de caracteres
del S.O. En la pestaña de seguridad nos advierte que dejemos
seleccionado el uso de las nuevas políticas de seguridad que es la
opción por defecto. Podemos desactivarla si lo consideramos
necesario, pero en este caso dejamos seleccionado.
En
la pestaña “sample schemas” podemos definir si instalar las
bases de datos de ejemplo, seleccionamos la opción y presionamos
“Next”.
Ahora
nos pregunta si deseamos gestionar la instalación mediante un
control para GRID preexistente o si deseamos gestionar la instancia
con el gestor de Oracle y recibir notificaciones por mail. Dejamos
seleccionada la opción por defecto que es “Use database control
for database management”, es decir, gestionar la instancia con el
administrador local. Sacamos la selección de envío de
notificaciones puesto que solicita la configuración de un servidor
SMTP y eso es otra historia. Presionamos “Next” para continuar.
En
la pantalla actual debemos indicar si vamos a utilizar el sistema de
archivos del SO para el almacenamiento de la base de datos y nos
suguiere que si así lo hacemos coloquemos la ruta de un disco
diferente. También permite la opción del servicio automatizado de
almacenamiento, el cual determina por si solo las mejores ubicaciones
para los archivos. Dejamos la opción por defecto que es utilizar el
sistema de archivos y presionamos “Next”.
En
esta pantalla nos pregunta acerca de los resguardos automáticos, si
los habilitamos o no, y en el caso de seleccionar la primer opción
debemos indicar el tipo de almacenamiento que queramos para los
resguardos (sistema de archivos o automático, como en la pantalla
anterior). Dejamos la opción por defecto que es no hacer resguardos
automáticos y presionamos “Next”.
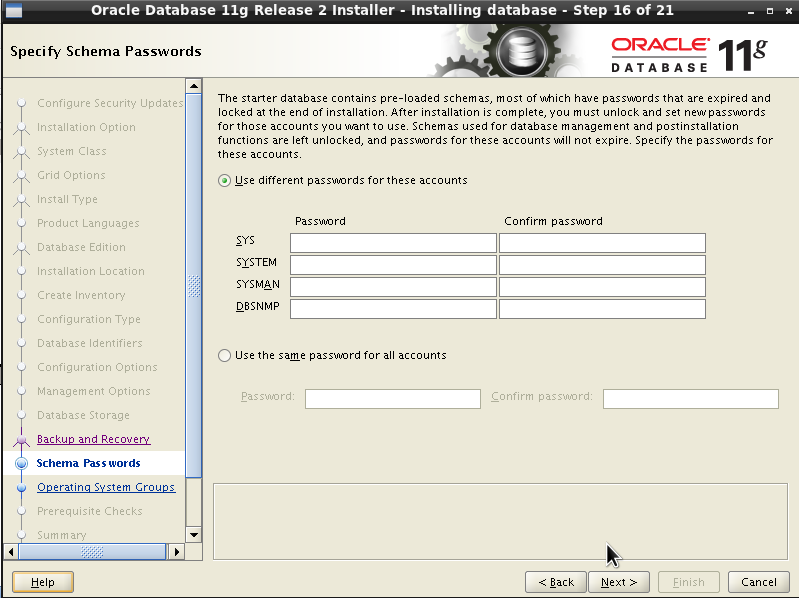
En
la pantalla actual nos solicita que ingresemos una contraseña
diferente para cada uno de los usuarios de administración para el
motor o bien que establezcamos la misma para todos. Por razones de
comodidad (y para evitar posibles olvidos y no tener que reinstalar
todo de nuevo :P) vamos a seleccionar la misma contraseña para
todos. Ingresamos la contraseña deseada. Si la contraseña no cumple
con las recomendaciones de seguridad se mostrará un mensaje.
Presionamos “Next”.
Ahora
nos solicita el grupo de usuarios a los que deben pertenecer los
usuarios de administración del motor para adquirir los mismos
permisos y así poder gestionar la base de datos. Dejamos las
opciones por defecto y presionamos “Next”.
El
asistente procede a realizar una comprobación del sistema:
 El
asistente realiza un chequeo de los requisitos del sistema y luego
nos informa de los problemas encontrados, si es que los hay:
El
asistente realiza un chequeo de los requisitos del sistema y luego
nos informa de los problemas encontrados, si es que los hay:
En
este caso se muestran problemas con algunos parámetros del kernel
que no son los adecuados, el tamaño de la memoria está por debajo
del mínimo y existen problemas de dependencias de paquetes. Los
problemas con los parámetros del kernel pueden arreglarse.
Presionamos “Fix & check again” y abrimos una consola, nos
logueamos como root y ejecutamos el siguiente script generado por el
asistente:
#
/tmp/CVU_11.2.0.1.0_bda/runfixup.sh
Response
file being used is :/tmp/CVU_11.2.0.1.0_bda/fixup.response
Enable
file being used is :/tmp/CVU_11.2.0.1.0_bda/fixup.enable
Log
file location: /tmp/CVU_11.2.0.1.0_bda/orarun.log
uid=502(bda)
gid=502(bda) groups=502(bda)
Ahora
bien, estos errores pueden ignorarse y continuar con la instalación,
pero lo más probable es que empiecen a aparecer errores y la
instalación falle. Es por eso que si encontramos problemas de
memoria y de espacio de intercambio es mejor volver a instalar
nuestro S.O o tratar de modificar esos aspectos si es posible.
Los
problemas de dependencias de paquetes se solucionan fácilmente.
Visitamos la página rpmfind.net y buscamos por los paquetes que
faltan, los descargamos y los instalamos mediante el siguiente
comando:
#
rpm -i <paquete1.rpm> ... <paqueteN.rpm>
El
en caso del paquete pdksh, que es un intérprete de comandos que
ninguno de los usuarios configurados utiliza y en Fedora se llama ksh
(Korn Shell), no se puede instalar porque entra con conflicto con
otro intérprete que se llama bash, que es el utilizado de manera
predefinida. Esta dependencia puede ser ignorada sin ningún
problema.
Finalmente
nos muestra un árbol de resumen con la posibilidad de guardar el
archivo de respuestas para una futura instalación. Presionamos
“Finish” para que comience la instalación.
El
asistente muestra las tareas que se están realizando y el progreso
de las mismas.
En
el caso de esta instalación ocurrió un error debido a que la
versión instalada del compilador de C es más reciente que la
requerida por la instalación, de modo que tuvimos que solucionarlo
editando un archivo de instalación:
Guardamos
el archivo y presionamos “Retry” en el asistente para que vuelva
a intentar realizar la acción errónea.
Al
final de la instalación nos pide que ejecutemos uno o más scripts
como superusuario:
#
/home/bda/app/oraInventory/orainstRoot.sh
Changing
permissions of /home/bda/app/oraInventory.
Adding
read,write permissions for group.
Removing
read,write,execute permissions for world.
Changing
groupname of /home/bda/app/oraInventory to bda.
The
execution of the script is complete.
#
/home/bda/app/bda/product/11.2.0/dbhome_1/root.sh
Running
Oracle 11g root.sh script...
The
following environment variables are set as:
ORACLE_OWNER= bda
ORACLE_HOME=
/home/bda/app/bda/product/11.2.0/dbhome_1
Enter
the full pathname of the local bin directory: [/usr/local/bin]:
Copying
dbhome to /usr/local/bin ...
Copying
oraenv to /usr/local/bin ...
Copying
coraenv to /usr/local/bin ...
Creating
/etc/oratab file...
Entries
will be added to the /etc/oratab file as needed by
Database
Configuration Assistant when a database is created
Finished
running generic part of root.sh script.
Now
product-specific root actions will be performed.
Finished
product-specific root actions.
Al
finalizar la instalación el asistente nos indica que se ha llevado a
cabo con éxito.
Una
vez que el asistente ah finalizado, se inicia el servicio de bases de
datos y el servicio de la consola de administración en un contenedor
web local. Para acceder al mismo nos proporciona una dirección, la
cual accedemos mediante un navegador web:
Al
acceder a esta dirección se nos presenta la siguiente página web:
Aquí
nos solicita que ingresemos un nombre de usuario y contraseña. Éstos
datos son los que nos solicitó durante la instalación. Ingresamos
mediante el usuario “SYSTEM” y la contraseña que configuramos en
la instalación.
La
siguiente pantalla nos muestra un resumen muy completo del estado
actual de los componentes del RDBMS, como por ejemplo el uso del
procesador, el tiempo de respuesta para las consultas, el estado de
la escucha de red, como así también algunas advertencias sobre
recomendaciones de seguridad y rendimiento. También nos informa
sobre el tamaño de la base de datos, algunos problemas que pueda
tener y el espacio disponible. Podemos ver el estado general del
motor de un vistaso.
Haciendo
clic en “Esquema” nos muestra una pantalla en la que podremos
modificar los objetos del esquema de la base de datos, como las
tablas, las vistas, las secuencias, los índices, las vistas, etc.
Luego en la pestaña de “Movimiento de datos” encontramos las
opciones para exportar e importar datos a la base de datos.
Y así ya tenemos instalado nuestro motor de bases de datos! :)
Hasta la próxima!!